瞎写—MPC—Shader—傻瓜教程 Ver.1.0
2005-12-19 15:33 | mazda
本文的意图在于帮助大家和我一起瞎玩。没有别的意思,阅读本文不需了解D3D,只需要基本的数学知识即可,如果接触过C语言那很好。
一:VMR9 renderless renderer的大致特点和MPC的运用方式。
如果想仔细了解VMR,那么请自行参阅DirectShow文档(挺长,挺庞大的)本文旨在成为MPC shader编写傻瓜教程,所以不对DS,VMR原理和运用做详细解释。
不同于其他的video渲染方式,VMR9 renderless方式不会将按照时间编排好的影片图像帧(或者是多个streams input的图像混合)直接放映出来,而是存为一个纹理表面(可以简单地认为就是存在于显存/AGP内存/内存中的,反正就是存在于一个可以被GPU访问的位置的图片)。后面的事……就是你想怎么做就怎么做了,比如你可以建个立方体,把纹理贴上,建个模型,把纹理贴上,建个…………,就是这样,这个叫做custom allocator。
至于MPC,它做的就比较简单直接了,它按照显示窗口大小画了一个四边形(window aligned Quad),然后就是把这张纹理贴上去,然后再加上字幕,如果窗口大小和纹理大小不同的话,它会做一下过滤和拉伸,这个过滤可以选择:硬件双线性过滤,pixel shader实现的双线性过滤,pixel shader实现的双立方过滤(可以选择立方插值的参数s),其中,效果最佳的是双立方插值。而线性过滤,在放大缩小倍数大于2的情况下就会比较严重失真。
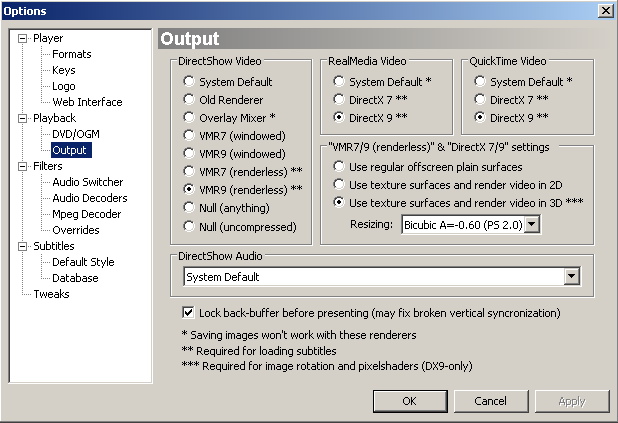
那么MPC的shader作用于何时呢?它是作用于将帧渲染到纹理之后,添加字幕,纹理拉伸,过滤之前。用一个流程来表示就是file source -> source filter -> decoder -> stream mix -> render to texture surface -> custom shader -> blend with subtitle ->stretch and filter。从原理上讲,它将movie frame texture经过custom shader变换写入了一个新的texture。而这个texture的内容就是我们看到的最终内容。
二:纹理坐标,纹理空间的基本概念
将一张纹理贴到一个物体上需要一定法则,映射是一种通用的方式,将纹理的每个元素(texel)映射到物体所占据的相应像素(pixel)上去。于是,每个像素就需要一个纹理坐标(u,v),这个以uv为坐标轴的空间叫做纹理空间,纹理空间属于纹理本地空间。在D3D中规定,一张纹理的左上角的纹理空间坐标为(0,0),右下角的纹理空间坐标为(1,1),如下图,如果window aligned quad的左上角的uv信息定为(0,0),右下角uv信息定为(1,1)那么经过映射,纹理就会正好贴在这个quad上面。
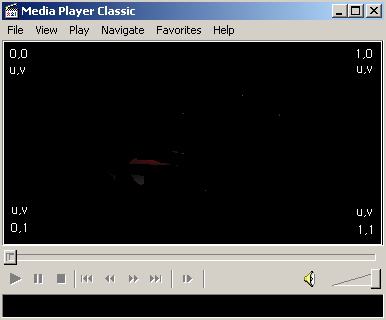
图一:screen aligned quad的uv分布

图二:纹理的纹理空间坐标定义
题外话,其实按照D3D的光栅化规则,这个window aligned quad应该向左上移动半个像素。因为光栅化是按照pixel center来的,而纹理空间则是按照texel corner定义的。只有平移半个像素才能保证准确,也可以更好地适应MSAA……扯远了。
三:HLSL,颜色表示。
使用MPC的custom shader,由于在MPC中需要使用HLSL编写shader,所以首先要了解HLSL里面的颜色表示法,HLSL中,尤其是MPC中,颜色基本都是使用XRGB表示(X代表保留位),一般将其表示为一个四维矢量,数据类型是float4。比如float4 color;,那么接下来就可以用color.x,color.y,color.z,来分别访问R,G,B三个分量了。
众所周知,对于24位,或者32位图像来说来说,RGB每个通道都是8位,转化为10进制就是0-255的整数,不过在HLSL中情况不同,0对应的是float(0.0)而255对应的是float(1.0),所以白色表示不再是(255,255,255)而是float3(1.0,1.0,1.0)或者float4(1.0,1.0,1.0,1.0)。
四:HLSL运作基本方式,MPC中的custom shader运作方式。纹理映射方式
基于光栅化的渲染是现今的GPU通用方式,对于MPC中HLSL(属于pixel shader范畴),它是一段code,一次操作的目标是一个pixel。它会自动重复作用于需要的每一个pixel。由于custom shader作用于stretch之前,所以作用的像素数量和影片尺寸相关,比如影片尺寸是320x240,那么这段code自动针对320x240个像素逐个执行一遍。写入一个新的320x240的纹理当中。
HLSL中的最简单的2D纹理映射函数是tex2D(s,t);两个参数,第一个是一个sampler,它代表的是目标纹理和纹理过滤,寻址方式,第二个参数是一个float2,也就是纹理坐标uv。它返回一个颜色值float4,这就是:纹理s中,纹理坐标t处的颜色之意。
五:一个最简单的例子,输出原始图像。
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
return tex2D(s0,tex);
}
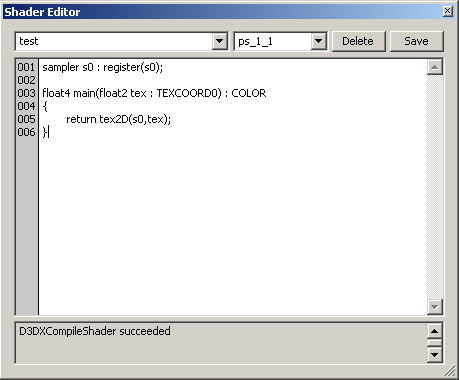
图三:一个典型的shader编辑器,进入方法:菜单play->shaders->edit
让我们看看这段程序,第一行定义了一个sampler,将pixel shader寄存器s0与我们定义的sampler s0绑定,在MPC中,寄存器s0就是影片图像所对应的纹理。换句话说,MPC中,这句话是万年不变的。:)
下面是HLSL主函数,float4 main(float2 tex : TEXCOORD0) : COLOR,它代表的意思是,输出一个float4变量,将这个float4变量作为COLOR(作为render target 0中的颜色,关于render target,后面会解释)。这个函数有一个输入参数,就是作为0号纹理坐标(TEXCOORD0)的float2类型的tex。
由于MPC的custom shader相当局限,所以事实上,就函数声明来说,float4 main(float2 tex : TEXCOORD0) : COLOR 这句话也是万年不变的……:)
HLSL接近C的语法,下面的这行return tex2D(s0,tex);,意义十分明显,结合上一节的解释,它代表返回一个float4值,这个值就是影片对应纹理在纹理坐标tex处的颜色。
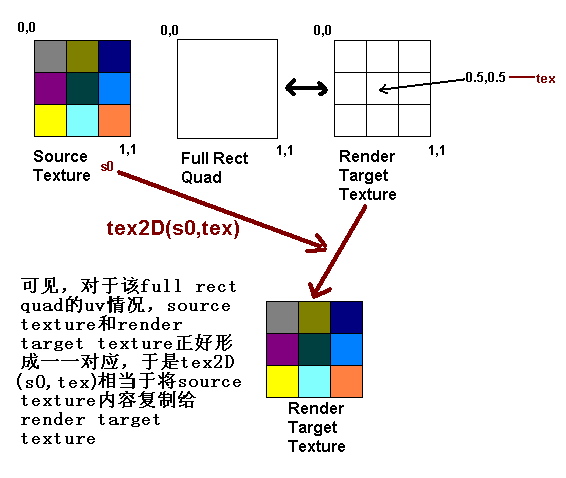
在这里就需要说明作为输入的TEXCOORD0的内容了,在MPC中,我们知道原纹理要经过shader处理后写入一个新的同样大小的纹理中,所以事实上它绘制了一个full rect quad(全区域矩形)并把新的纹理作为该次绘制的输出对象——render target,关于render target的理解,其实非常简单,就好比,显卡通常把屏幕对应的显存缓冲区域作为render target、而打印机则通常把打印纸作为render target、如果显卡把一个纹理作为render target的话,那么它绘制的东西就不显示于屏幕上,而绘制到该纹理中。当render target是屏幕对应的缓冲区时,full rect quad对应的就是整个屏幕区域(忽略viewport),而如果render target是一个纹理的话,那么这个full rect quad对应的就是整个纹理。而quad的四角纹理坐标uv如下图所示,左上0,0;右下1,1;uv将输入VertexShader中的输出寄存器t0。经过光栅化后,作为pixelshader的输入寄存器t0,也就是TEXCOORD0的内容tex输入。存放的就是该uv对于每个render target中像素的离散值,我们将问题简化,忽略光栅化规则的像素中心点的0.5偏移,这样比较直观,假设原纹理是3x3大小,目标纹理(render target)用样也是3x3大小。于是full rect quad对应的就是这个3x3大小的render target。所以光栅化后该render target左上角对应的tex就是直接来自quad左上角的0,0,同样右下角对应的tex是1,1,而正中的像素对应的tex就是经过光栅化离散得出的0.5,0.5,很容易看出原纹理的uv空间坐标和目标纹理的tex一一对应。于是经过tex2D(s0,tex)后,就等于将原纹理复制到了目标纹理上。如何?试试吧
六:稍微进一步:太亮?太暗?gamma校正
变亮20%
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
return color0+color0*float4(0.2,0.2,0.2,0.0);
}
变暗20%
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
return color0*float4(0.8,0.8,0.8,1.0);
}
点评,设三个float4——color0,color1,scale;
color1 = color0*scale;
则代表
color1.x = color0.x*scale.x;
color1.y = color0.y*scale.y;
color1.z = color0.z*scale.z;
color1.w = color0.w*scale.w;
这里是对位相乘,和矢量乘法(点积)不同。
如果想得到矢量点积,请使用mul(x,y);
比如float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );其中color0.xyz表示以color0的xyz元素构成的一个3维向量,lum = color0.x*0.3 + color0.y*0.59 + color0.z*0.11;
于是,灰度转换shader呼之欲出
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
return float4(lum,lum,lum,1.0);
}
再回到增亮的shader,为何使用color0+color0*float4(0.2,0.2,0.2,0.0);而不是color0*float4(1.2,1.2,1.2,1.0);这是为了照顾ps1.x,看见图三的右上选择框了么?那个表示的就是将HLSL编译为哪一种ps目标,版本越高,HLSL就越灵活,当然,硬件功能要求也就越强。对于ps1.x来说,常量寄存器不能储存超过1的数值,所以如果用float4(1.2,1.2,1.2,1.0)运行时会直接当作float4(1.0,1.0,1.0,1.0)处理,也可以说,是HLSL编译器比较弱智,不能自动转化为color0+color0*float4(0.2,0.2,0.2,0.0);这种形势,不过说到底,HLSL从一开始就是为ps2.0和以上版本诞生的。
再看一个,让亮的更亮,暗的更暗
可编译为ps1.x版本的
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
return 2.0*color0 * float4(lum,lum,lum,1.0);
}
编译为ps2.0或以上版本的
sampler s0 : register(s0);
#define Pi 3.14159 //预定义 pi
#define scalefactor 0.6 //亮度缩放因子
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
float scale = 1.0 + scalefactor*sin((lum-0.5)*Pi); //一个简单的自定义亮度缩放曲线,0.5的亮度是分界点,暗的更暗,亮的更亮
return color0 * float4(scale,scale,scale,1.0);
}
结合上面的三个例子,这个应该很容易理解。
下面说一个稍微复杂和更有实际意义的,就是gamma校正,gamma校正的原因是,人眼对颜色的亮度敏感性和CRT输入电压不成线性比例,而是一个近似指数关系,windows默认该指数是2.2。所以默认进行了一次原始信号的1/2.2指数补偿,这样保证了线性输入输出。而实际情况中gamma值则根据显示器不同而有差别,所以需要校正,不过,可能有人发现了overlay的gamma设置对VMR行不通,所以,这时就需要使用shader进行校正了。
sampler s0 : register(s0);
#define gamma_origin 2.2 //默认gamma
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float gamma = 1.8; //实际显示器gamma值
float4 color0 = tex2D(s0,tex); //原始经过2.2修正的图像
float gamma_scale = gamma_origin/gamma;
color0.xyz = pow(color0.xyz,float3(gamma_scale,gamma_scale,gamma_scale) );//指数校正
return color0;
}
这个shader必须用ps_2_0或者以上作为编译目标,因为ps_2_0以下不支持指数函数和变量倒数。
七:纹理坐标还能给我们什么信息?
float2 tex : TEXCOORD0是输入变量,代表了该像素处的uv坐标。除了tex2D(tex,s0);外,tex还有没有其他用法?当然,先举一个例子
我们知道,(0.5,0.5)的uv代表纹理中心,那么tex-float2(0.5,0.5)代表从纹理中心指向tex所代表像素的矢量,那么我们可以做一些文章了
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float len = length(tex.xy-float2(0.5,0.5)); //距中心长度
float falloff = saturate(1.0 - len*3.0); //一个简单的随距离衰减
return color0*float4(falloff,falloff,falloff,1.0);
}
这是一个简单的针孔效果,其中length()的意义是求向量的模长,比如length(float2 v) = sqrt(v.x*v.x+v.y*v.y);length(float3 v) = sqrt(v.x*v.x+v.y*v.y+v.z*v.z);等,而saturate()的意义是将参量截断到[0,1]之间。比如saturate(float2(-0.5,1.5) )的结果就是float2(0.0,1.0)
我们稍微修改一下,利用mpc的一个内建时间参量。做出一点动态的东西
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define clock (p0[3]) //c0.w存放时间
#define Pi 3.14159 //预定义 pi
#define freq 0.5 //循环频率
#define rad 0.2 //循环半径
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float sine,cosine;
float cycletick = frac(clock*freq)*2.0*Pi; //时间循环
sincos(cycletick,sine,cosine); //求出正弦余弦
float2 tempcenter = float2(0.5+rad*cosine,0.5+rad*sine); //针孔的中心点
float4 color0 = tex2D(s0,tex);
float len = length(tex.xy-tempcenter); //距中心长度
float falloff = saturate(1.0 - len*3.0); //一个简单的随距离衰减
return color0*float4(falloff,falloff,falloff,1.0);
}
效果的话,自己试试咯。这两个都需要ps2.0支持。
八:纹理坐标修改后再次使用?
对中心缩放
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float2 scalefactor = float2(1.5,1.5);
float2 newtex = (tex-float2(0.5,0.5))*scalefactor+ float2(0.5,0.5);
float4 color0;
color0 = tex2D(s0,newtex);
if(newtex.x < 0.0 || newtex.x > 1.0 || newtex.y < 0.0 ||newtex.y >1.0)
color0 = float4(0.0,0.0,0.0,1.0);
return color0;
}
有一个基本公式,比如一个物体,要以某一点为中心进行变换操作,如旋转,缩放等,那么需要的操作是
1:将坐标系原点转换至中心
2:进行变换操作
3:将坐标系原点移回。
所以对于上面的情况
tex-float2(0.5,0.5)将纹理空间坐标原点移至纹理中心
*scalfactor进行缩放变换
+float2(0.5,0.5)将坐标原点移回左上角
然后不要忘记将新纹理坐标在(0,0)(1,1)之外的点设定为黑色。
下面再示范一下旋转变换
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define clock (p0[3]) //c0.w存放时间
#define Pi 3.14159 //预定义 pi
#define freq 0.2 //循环频率
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float sine,cosine;
float cycletick = frac(clock*freq)*2.0*Pi; //时间循环
sincos(cycletick,sine,cosine); //求出正弦余弦
float2x2 rotate_matrix = {cosine,sine,-sine,cosine};//构造旋转矩阵
float2 newtex = mul((tex-float2(0.5,0.5)),rotate_matrix)+ float2(0.5,0.5);//平移至中心,旋转变换,平移回
float4 color0;
color0 = tex2D(s0,newtex);
if(newtex.x < 0.0 || newtex.x > 1.0 || newtex.y < 0.0 ||newtex.y >1.0)
color0 = float4(0.0,0.0,0.0,1.0);
return color0;
}
其中,float2x2代表一个2x2的以float为元素的矩阵,而旋转可以用向量与矩阵相乘来表示,mul的命令本身提供了众多函数重载,适应不同的参数类型。
本节的例子同样需要ps2.0来编译
九:相邻texel的使用,滤波的使用
所谓滤波从理论上讲是将信号与滤波核做一下卷积,换到图像滤波的领域来,通俗地讲就是存在一个滤波核,通常覆盖m*m个像素,滤波核也表示为m*m的方阵。方阵的每一个元素代表所对应的像素的滤波权重(见下图)。然后以图像中的每一个像素为中心作用这个滤波核,对该核所包含的所有像素权重求和,得出的结果写入一个新的图像中,该图像就是滤波后的图像。
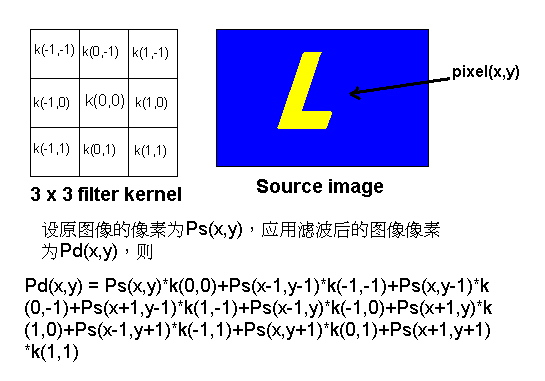
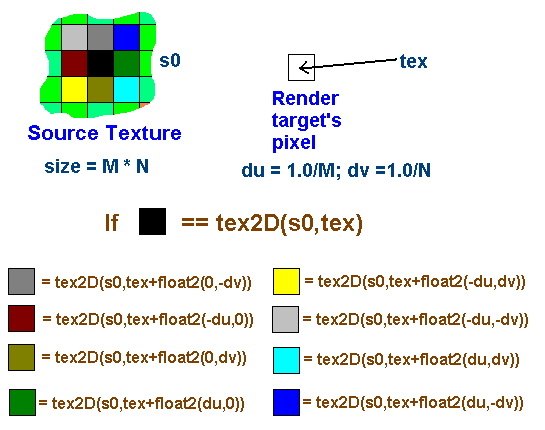
下面的问题是如何在MPC的shader中获得相邻像素。如下图,设原纹理大小为M*N个texel,于是每个texel的uv尺寸为(1.0/M,1.0/N),所以可以通过将tex偏移再tex2D来取得相邻处的texel。
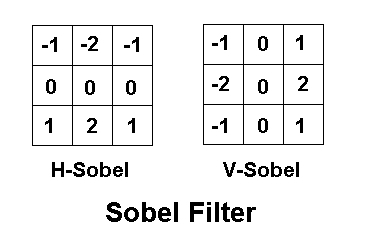
下面示范解释一下colored edge(稍微改进了一下)的实现。它判断边缘使用的是sobel filter,sobel filter如下所示。事实上,sobel filter相当于差商求偏导数。也就是说,它表示的是颜色在不同方向(u方向或v方向)的变化剧烈程度,如果变化剧烈,超过一定阈值,那么就判断为边缘。
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define width (p0[0]) //c0.x存放原纹理长度
#define height (p0[1]) //c0.y存放原纹理高度
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float dx = 1/width; //相邻texel的u偏移
float dy = 1/height; //相邻texel的v偏移
float4 c0 = tex2D(s0, tex);
float4 c1 = tex2D(s0, tex + float2(-dx,-dy));
float4 c2 = tex2D(s0, tex + float2(0,-dy));
float4 c3 = tex2D(s0, tex + float2(dx,-dy));
float4 c4 = tex2D(s0, tex + float2(-dx,0));
float4 c5 = tex2D(s0, tex + float2(dx,0));
float4 c6 = tex2D(s0, tex + float2(-dx,dy));
float4 c7 = tex2D(s0, tex + float2(0,dy));
float4 c8 = tex2D(s0, tex + float2(dx,dy)); //取得3x3共9个texel
float4 delta1 = (c1+2.0*c2+c3-c6-2.0*c7-c8); //水平sobel filter
float4 delta2 = (c1+2.0*c4+c6-c3-2.0*c5-c8); //垂直sobel filter
float value = mul (delta1.xyz,delta1.xyz);
value += mul (delta2.xyz,delta2.xyz); //由于是rgb3个分量,所以求模长平方来确定绝对值大小,不做sqrt为了节省计算资源
float colorsat = saturate(1.3-3.0*value); //设定饱和曲线,可见,由sobel filter确定的边缘处(value较大)colorsat为0,而非边缘处(value接近0)则为1
return c0+float4(colorsat,colorsat,colorsat,0.0); //饱和原色,非边缘处,颜色将会饱和至白色,而边缘处,颜色不变。所以带有颜色的描边便显示出来。
}
其他的,比如sharpen filter,gaussian blur filter等等实现方法也是类似,只要知道滤波核,剩下的不过是:1:用纹理坐标偏移+tex2D得出滤波核对应的texel,2:乘上滤波核的权重因子并相加。即可
十:硬件,性能的考虑(这部分相对而言专业化一些)
由于MPC中的HLSL最终是由GPU硬件执行,所以硬件特性和执行效率就是必须考虑的问题。
首先我们需要考虑HLSL指令和最终生成的GPU指令的对应关系,从而对HLSL代码实际执行指令长度有一个大致估计。
就GPU而言,其pixel shader执行单元可以认为是一系列的矢量处理器配上标量处理器再加上纹理单元构成。所谓矢量处理器,所执行的GPU运算诸如(以下是GPU汇编指令,和HLSL指令有区别)
add——vec1+vec2——矢量对位相加
mul——vec1*vec2——矢量对位相乘
mad——vec1*vec2+vec3——矢量对位乘加
dp3——vec1.x*vec2.x+vec1.y*vec2.y+vec1.z*vec2.z——矢量点积
等运算,而标量单元负责的是诸如
pow——scar1^scar2——标量幂运算
rcp——1.0/scar1——标量倒数运算
rsq——1.0/sqrt(scar1)——标量方根倒数
log——log2(scar1)——2为底的对数
等等
而纹理单元,执行的自然是
texld——纹理采样函数
下面列举一些HLSL指令对应的GPU指令数量和性质
float4 v1 = v2 + v3;——一条GPU加法指令
而float4 v1 = v2 + v3 + v4;——两条GPU加法指令
float4 v1 = v2 * v3 + v4;——一条GPU乘加指令
float4 v1 = mul(float4(v2),float4x4(m1));——一条GPU乘法mul加上3条GPU乘加mad。
而
float s1 = s2/s3——一条GPU标量倒数rcp加上一条GPU乘法
float s1 = sqrt(s2)——一条GPU标量平方根倒数rsq加上一条GPU标量倒数rcp
float3 v1 = pow(float3(v2),float3(v3) )——三条GPU标量指数运算
float3 v1 = float3(v2)/float3(v3)——三条GPU标量倒数+一条GPU矢量乘法
比如
tex2D(s0,tex)——一条纹理取样函数,无dependent texture read
tex2D(s0,tex+float2(0.6,-0.6))——一条矢量加法加上一条纹理取样,一级dependent texture read
tex2D(s0,tex+tex2D(s0,tex+float2(0.6,0.6)).xy)——两条矢量加法加上两条纹理取样指令,两级dependent texture read
tex2D(s0,tex+tex2D(s0,tex).xy)+v1——两条矢量加法加上两条纹理取样,一级dependent texture read
等等……
在MPC的HLSL编译目标(compile target)选项中,有意义的包括ps_1_1,ps_1_3,ps_1_4,ps_2_0,ps_3_0。HLSL code的结构复杂度、指令的复杂性、指令数多寡决定了它最低需要的编译目标。
ps_1_1和ps_1_3在实际应用中差别甚微。都属于限制非常大的编译目标,主要限制是:
1:最大指令数目限制严重,不能超过8条算术指令(尽管其实可以不超过3维的矢量运算与标量运算并发(co-issue)所以最多是16条算术指令,但是不用指望HLSL编译器能够强大到如此程度)和4条纹理指令(ps1.1-1.3的纹理指令其实比较复杂,属于组合功能方式,但是在MPC中基本用不上)
2:无复杂运算指令,诸如rcp,rsq,log,pow等全部没有
3:寄存器数值范围很窄,比如float s1 = 1.5 * s2;就会自动变成float s1 = 1.0 * s2;(也就是1.5超出了范围),只能写成float s1 = s2+0.5*s2;才能正确编译
4:无dependent texture read。而tex基本可以认为无法操作
5:分支什么的就基本不用指望了。除了像if(s1>0.0){s2 = 1.0;}else{s2 = 0.0;}这种极其简单的。
ps_1_1级别的硬件,比较流行的是Nvidia Geforce 3
ps_1_3级别的硬件,比较流行的是Nvidia Geforce 4Ti
ps_1_4比ps_1_3适应性广一些包括
1:最大指令数限制有所松动,算术指令翻倍,纹理指令翻2倍。
2:支持一定限度的dependent texture read(1级),tex可以进行一定程度的操作
ps_1_4级别的硬件,比较流行的是ATI Radeon8500,9000-9200
事实上,由于ps1.x属于定点数结构,所以有一些移位指令可以使用,比如mul_x2,add_x2代表将结果相加后左移一位,相当于乘二。这也是为何第六节的第四个程序有ps1.x版本的原因。不过说到底,ps1.x不是为HLSL准备的。
ps_2_0是HLSL诞生时的默认编译对象
1:支持绝大多数的HLSL函数。
2:64条算术指令,32条纹理指令,最多4级的dependent texture read
3:全部浮点流水线,数据范围精度增强。
4:尽管ps_2_0没有硬件支持的动态分支,不过可以实现一定程度的分支,只不过每个分支都要跑一遍。也就是效率不会很高
ps_2_0级别的硬件包括Nvidia GeforceFx系列(ps_2_a)ATI Radeon 9500及以上X700以下(ps_2_0)X700,X800,X850系列(ps_2_b)
ps_3_0是当前PC上的最高pixel shader版本
1:比ps_2_0增加了一些指令
2:硬件支持分支,循环
3:最大指令数大大增加,不再有纹理算术指令数量分配的限制
4:dependent texture read级数没有限制
ps_3_0级别硬件包括Nvidia Geforce 6系列,7系列,ATI Radeon X1xxx系列
所以,编写HLSL请考虑自身硬件的功能等级。
以下是一些简单的提升性能的考虑
1:如果可以,使用ps1.x编译对象能获得最佳性能,如果该HLSL code不能使用ps1.x编译对象,那么请使用可用的最高ps版本的编译对象,如Geforce6系列就请使用ps_3_0编译对象。
2:在许可的情况下尽量减少使用复杂运算指令,诸如pow,sin,cos,asin,acos,sqrt等。
3:对于Nvidia Geforce Fx和6系列,推荐将float(FP32)替换为half(FP16)以提高性能。
4:对于向量来说,选择需要的最小维数,比如能用float3(half3)就不要用float4(half4),能用标量就不要用矢量
5:动态分支不要太多,除非你用的是X1800XT……
附:一些相关资料
HLSL参考:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/directx9_c/dx9_graphics_reference_hlsl.asp
DirectShow相关
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/directshow/htm/directshow.asp
一篇不错的介绍数字图像处理的文章
http://www.gamedev.net/reference/articles/article2007.asp
一:VMR9 renderless renderer的大致特点和MPC的运用方式。
如果想仔细了解VMR,那么请自行参阅DirectShow文档(挺长,挺庞大的)本文旨在成为MPC shader编写傻瓜教程,所以不对DS,VMR原理和运用做详细解释。
不同于其他的video渲染方式,VMR9 renderless方式不会将按照时间编排好的影片图像帧(或者是多个streams input的图像混合)直接放映出来,而是存为一个纹理表面(可以简单地认为就是存在于显存/AGP内存/内存中的,反正就是存在于一个可以被GPU访问的位置的图片)。后面的事……就是你想怎么做就怎么做了,比如你可以建个立方体,把纹理贴上,建个模型,把纹理贴上,建个…………,就是这样,这个叫做custom allocator。
至于MPC,它做的就比较简单直接了,它按照显示窗口大小画了一个四边形(window aligned Quad),然后就是把这张纹理贴上去,然后再加上字幕,如果窗口大小和纹理大小不同的话,它会做一下过滤和拉伸,这个过滤可以选择:硬件双线性过滤,pixel shader实现的双线性过滤,pixel shader实现的双立方过滤(可以选择立方插值的参数s),其中,效果最佳的是双立方插值。而线性过滤,在放大缩小倍数大于2的情况下就会比较严重失真。
那么MPC的shader作用于何时呢?它是作用于将帧渲染到纹理之后,添加字幕,纹理拉伸,过滤之前。用一个流程来表示就是file source -> source filter -> decoder -> stream mix -> render to texture surface -> custom shader -> blend with subtitle ->stretch and filter。从原理上讲,它将movie frame texture经过custom shader变换写入了一个新的texture。而这个texture的内容就是我们看到的最终内容。
二:纹理坐标,纹理空间的基本概念
将一张纹理贴到一个物体上需要一定法则,映射是一种通用的方式,将纹理的每个元素(texel)映射到物体所占据的相应像素(pixel)上去。于是,每个像素就需要一个纹理坐标(u,v),这个以uv为坐标轴的空间叫做纹理空间,纹理空间属于纹理本地空间。在D3D中规定,一张纹理的左上角的纹理空间坐标为(0,0),右下角的纹理空间坐标为(1,1),如下图,如果window aligned quad的左上角的uv信息定为(0,0),右下角uv信息定为(1,1)那么经过映射,纹理就会正好贴在这个quad上面。
图一:screen aligned quad的uv分布
图二:纹理的纹理空间坐标定义
题外话,其实按照D3D的光栅化规则,这个window aligned quad应该向左上移动半个像素。因为光栅化是按照pixel center来的,而纹理空间则是按照texel corner定义的。只有平移半个像素才能保证准确,也可以更好地适应MSAA……扯远了。
三:HLSL,颜色表示。
使用MPC的custom shader,由于在MPC中需要使用HLSL编写shader,所以首先要了解HLSL里面的颜色表示法,HLSL中,尤其是MPC中,颜色基本都是使用XRGB表示(X代表保留位),一般将其表示为一个四维矢量,数据类型是float4。比如float4 color;,那么接下来就可以用color.x,color.y,color.z,来分别访问R,G,B三个分量了。
众所周知,对于24位,或者32位图像来说来说,RGB每个通道都是8位,转化为10进制就是0-255的整数,不过在HLSL中情况不同,0对应的是float(0.0)而255对应的是float(1.0),所以白色表示不再是(255,255,255)而是float3(1.0,1.0,1.0)或者float4(1.0,1.0,1.0,1.0)。
四:HLSL运作基本方式,MPC中的custom shader运作方式。纹理映射方式
基于光栅化的渲染是现今的GPU通用方式,对于MPC中HLSL(属于pixel shader范畴),它是一段code,一次操作的目标是一个pixel。它会自动重复作用于需要的每一个pixel。由于custom shader作用于stretch之前,所以作用的像素数量和影片尺寸相关,比如影片尺寸是320x240,那么这段code自动针对320x240个像素逐个执行一遍。写入一个新的320x240的纹理当中。
HLSL中的最简单的2D纹理映射函数是tex2D(s,t);两个参数,第一个是一个sampler,它代表的是目标纹理和纹理过滤,寻址方式,第二个参数是一个float2,也就是纹理坐标uv。它返回一个颜色值float4,这就是:纹理s中,纹理坐标t处的颜色之意。
五:一个最简单的例子,输出原始图像。
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
return tex2D(s0,tex);
}
图三:一个典型的shader编辑器,进入方法:菜单play->shaders->edit
让我们看看这段程序,第一行定义了一个sampler,将pixel shader寄存器s0与我们定义的sampler s0绑定,在MPC中,寄存器s0就是影片图像所对应的纹理。换句话说,MPC中,这句话是万年不变的。:)
下面是HLSL主函数,float4 main(float2 tex : TEXCOORD0) : COLOR,它代表的意思是,输出一个float4变量,将这个float4变量作为COLOR(作为render target 0中的颜色,关于render target,后面会解释)。这个函数有一个输入参数,就是作为0号纹理坐标(TEXCOORD0)的float2类型的tex。
由于MPC的custom shader相当局限,所以事实上,就函数声明来说,float4 main(float2 tex : TEXCOORD0) : COLOR 这句话也是万年不变的……:)
HLSL接近C的语法,下面的这行return tex2D(s0,tex);,意义十分明显,结合上一节的解释,它代表返回一个float4值,这个值就是影片对应纹理在纹理坐标tex处的颜色。
在这里就需要说明作为输入的TEXCOORD0的内容了,在MPC中,我们知道原纹理要经过shader处理后写入一个新的同样大小的纹理中,所以事实上它绘制了一个full rect quad(全区域矩形)并把新的纹理作为该次绘制的输出对象——render target,关于render target的理解,其实非常简单,就好比,显卡通常把屏幕对应的显存缓冲区域作为render target、而打印机则通常把打印纸作为render target、如果显卡把一个纹理作为render target的话,那么它绘制的东西就不显示于屏幕上,而绘制到该纹理中。当render target是屏幕对应的缓冲区时,full rect quad对应的就是整个屏幕区域(忽略viewport),而如果render target是一个纹理的话,那么这个full rect quad对应的就是整个纹理。而quad的四角纹理坐标uv如下图所示,左上0,0;右下1,1;uv将输入VertexShader中的输出寄存器t0。经过光栅化后,作为pixelshader的输入寄存器t0,也就是TEXCOORD0的内容tex输入。存放的就是该uv对于每个render target中像素的离散值,我们将问题简化,忽略光栅化规则的像素中心点的0.5偏移,这样比较直观,假设原纹理是3x3大小,目标纹理(render target)用样也是3x3大小。于是full rect quad对应的就是这个3x3大小的render target。所以光栅化后该render target左上角对应的tex就是直接来自quad左上角的0,0,同样右下角对应的tex是1,1,而正中的像素对应的tex就是经过光栅化离散得出的0.5,0.5,很容易看出原纹理的uv空间坐标和目标纹理的tex一一对应。于是经过tex2D(s0,tex)后,就等于将原纹理复制到了目标纹理上。如何?试试吧
六:稍微进一步:太亮?太暗?gamma校正
变亮20%
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
return color0+color0*float4(0.2,0.2,0.2,0.0);
}
变暗20%
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
return color0*float4(0.8,0.8,0.8,1.0);
}
点评,设三个float4——color0,color1,scale;
color1 = color0*scale;
则代表
color1.x = color0.x*scale.x;
color1.y = color0.y*scale.y;
color1.z = color0.z*scale.z;
color1.w = color0.w*scale.w;
这里是对位相乘,和矢量乘法(点积)不同。
如果想得到矢量点积,请使用mul(x,y);
比如float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );其中color0.xyz表示以color0的xyz元素构成的一个3维向量,lum = color0.x*0.3 + color0.y*0.59 + color0.z*0.11;
于是,灰度转换shader呼之欲出
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
return float4(lum,lum,lum,1.0);
}
再回到增亮的shader,为何使用color0+color0*float4(0.2,0.2,0.2,0.0);而不是color0*float4(1.2,1.2,1.2,1.0);这是为了照顾ps1.x,看见图三的右上选择框了么?那个表示的就是将HLSL编译为哪一种ps目标,版本越高,HLSL就越灵活,当然,硬件功能要求也就越强。对于ps1.x来说,常量寄存器不能储存超过1的数值,所以如果用float4(1.2,1.2,1.2,1.0)运行时会直接当作float4(1.0,1.0,1.0,1.0)处理,也可以说,是HLSL编译器比较弱智,不能自动转化为color0+color0*float4(0.2,0.2,0.2,0.0);这种形势,不过说到底,HLSL从一开始就是为ps2.0和以上版本诞生的。
再看一个,让亮的更亮,暗的更暗
可编译为ps1.x版本的
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
return 2.0*color0 * float4(lum,lum,lum,1.0);
}
编译为ps2.0或以上版本的
sampler s0 : register(s0);
#define Pi 3.14159 //预定义 pi
#define scalefactor 0.6 //亮度缩放因子
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float lum = mul(color0.xyz,float3(0.3,0.59,0.11) );
float scale = 1.0 + scalefactor*sin((lum-0.5)*Pi); //一个简单的自定义亮度缩放曲线,0.5的亮度是分界点,暗的更暗,亮的更亮
return color0 * float4(scale,scale,scale,1.0);
}
结合上面的三个例子,这个应该很容易理解。
下面说一个稍微复杂和更有实际意义的,就是gamma校正,gamma校正的原因是,人眼对颜色的亮度敏感性和CRT输入电压不成线性比例,而是一个近似指数关系,windows默认该指数是2.2。所以默认进行了一次原始信号的1/2.2指数补偿,这样保证了线性输入输出。而实际情况中gamma值则根据显示器不同而有差别,所以需要校正,不过,可能有人发现了overlay的gamma设置对VMR行不通,所以,这时就需要使用shader进行校正了。
sampler s0 : register(s0);
#define gamma_origin 2.2 //默认gamma
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float gamma = 1.8; //实际显示器gamma值
float4 color0 = tex2D(s0,tex); //原始经过2.2修正的图像
float gamma_scale = gamma_origin/gamma;
color0.xyz = pow(color0.xyz,float3(gamma_scale,gamma_scale,gamma_scale) );//指数校正
return color0;
}
这个shader必须用ps_2_0或者以上作为编译目标,因为ps_2_0以下不支持指数函数和变量倒数。
七:纹理坐标还能给我们什么信息?
float2 tex : TEXCOORD0是输入变量,代表了该像素处的uv坐标。除了tex2D(tex,s0);外,tex还有没有其他用法?当然,先举一个例子
我们知道,(0.5,0.5)的uv代表纹理中心,那么tex-float2(0.5,0.5)代表从纹理中心指向tex所代表像素的矢量,那么我们可以做一些文章了
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float4 color0 = tex2D(s0,tex);
float len = length(tex.xy-float2(0.5,0.5)); //距中心长度
float falloff = saturate(1.0 - len*3.0); //一个简单的随距离衰减
return color0*float4(falloff,falloff,falloff,1.0);
}
这是一个简单的针孔效果,其中length()的意义是求向量的模长,比如length(float2 v) = sqrt(v.x*v.x+v.y*v.y);length(float3 v) = sqrt(v.x*v.x+v.y*v.y+v.z*v.z);等,而saturate()的意义是将参量截断到[0,1]之间。比如saturate(float2(-0.5,1.5) )的结果就是float2(0.0,1.0)
我们稍微修改一下,利用mpc的一个内建时间参量。做出一点动态的东西
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define clock (p0[3]) //c0.w存放时间
#define Pi 3.14159 //预定义 pi
#define freq 0.5 //循环频率
#define rad 0.2 //循环半径
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float sine,cosine;
float cycletick = frac(clock*freq)*2.0*Pi; //时间循环
sincos(cycletick,sine,cosine); //求出正弦余弦
float2 tempcenter = float2(0.5+rad*cosine,0.5+rad*sine); //针孔的中心点
float4 color0 = tex2D(s0,tex);
float len = length(tex.xy-tempcenter); //距中心长度
float falloff = saturate(1.0 - len*3.0); //一个简单的随距离衰减
return color0*float4(falloff,falloff,falloff,1.0);
}
效果的话,自己试试咯。这两个都需要ps2.0支持。
八:纹理坐标修改后再次使用?
对中心缩放
sampler s0 : register(s0);
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float2 scalefactor = float2(1.5,1.5);
float2 newtex = (tex-float2(0.5,0.5))*scalefactor+ float2(0.5,0.5);
float4 color0;
color0 = tex2D(s0,newtex);
if(newtex.x < 0.0 || newtex.x > 1.0 || newtex.y < 0.0 ||newtex.y >1.0)
color0 = float4(0.0,0.0,0.0,1.0);
return color0;
}
有一个基本公式,比如一个物体,要以某一点为中心进行变换操作,如旋转,缩放等,那么需要的操作是
1:将坐标系原点转换至中心
2:进行变换操作
3:将坐标系原点移回。
所以对于上面的情况
tex-float2(0.5,0.5)将纹理空间坐标原点移至纹理中心
*scalfactor进行缩放变换
+float2(0.5,0.5)将坐标原点移回左上角
然后不要忘记将新纹理坐标在(0,0)(1,1)之外的点设定为黑色。
下面再示范一下旋转变换
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define clock (p0[3]) //c0.w存放时间
#define Pi 3.14159 //预定义 pi
#define freq 0.2 //循环频率
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float sine,cosine;
float cycletick = frac(clock*freq)*2.0*Pi; //时间循环
sincos(cycletick,sine,cosine); //求出正弦余弦
float2x2 rotate_matrix = {cosine,sine,-sine,cosine};//构造旋转矩阵
float2 newtex = mul((tex-float2(0.5,0.5)),rotate_matrix)+ float2(0.5,0.5);//平移至中心,旋转变换,平移回
float4 color0;
color0 = tex2D(s0,newtex);
if(newtex.x < 0.0 || newtex.x > 1.0 || newtex.y < 0.0 ||newtex.y >1.0)
color0 = float4(0.0,0.0,0.0,1.0);
return color0;
}
其中,float2x2代表一个2x2的以float为元素的矩阵,而旋转可以用向量与矩阵相乘来表示,mul的命令本身提供了众多函数重载,适应不同的参数类型。
本节的例子同样需要ps2.0来编译
九:相邻texel的使用,滤波的使用
所谓滤波从理论上讲是将信号与滤波核做一下卷积,换到图像滤波的领域来,通俗地讲就是存在一个滤波核,通常覆盖m*m个像素,滤波核也表示为m*m的方阵。方阵的每一个元素代表所对应的像素的滤波权重(见下图)。然后以图像中的每一个像素为中心作用这个滤波核,对该核所包含的所有像素权重求和,得出的结果写入一个新的图像中,该图像就是滤波后的图像。
下面的问题是如何在MPC的shader中获得相邻像素。如下图,设原纹理大小为M*N个texel,于是每个texel的uv尺寸为(1.0/M,1.0/N),所以可以通过将tex偏移再tex2D来取得相邻处的texel。
下面示范解释一下colored edge(稍微改进了一下)的实现。它判断边缘使用的是sobel filter,sobel filter如下所示。事实上,sobel filter相当于差商求偏导数。也就是说,它表示的是颜色在不同方向(u方向或v方向)的变化剧烈程度,如果变化剧烈,超过一定阈值,那么就判断为边缘。
sampler s0 : register(s0);
float4 p0 : register(c0); //mpc内建的一些变量。存放于寄存器c0
#define width (p0[0]) //c0.x存放原纹理长度
#define height (p0[1]) //c0.y存放原纹理高度
float4 main(float2 tex : TEXCOORD0) : COLOR
{
float dx = 1/width; //相邻texel的u偏移
float dy = 1/height; //相邻texel的v偏移
float4 c0 = tex2D(s0, tex);
float4 c1 = tex2D(s0, tex + float2(-dx,-dy));
float4 c2 = tex2D(s0, tex + float2(0,-dy));
float4 c3 = tex2D(s0, tex + float2(dx,-dy));
float4 c4 = tex2D(s0, tex + float2(-dx,0));
float4 c5 = tex2D(s0, tex + float2(dx,0));
float4 c6 = tex2D(s0, tex + float2(-dx,dy));
float4 c7 = tex2D(s0, tex + float2(0,dy));
float4 c8 = tex2D(s0, tex + float2(dx,dy)); //取得3x3共9个texel
float4 delta1 = (c1+2.0*c2+c3-c6-2.0*c7-c8); //水平sobel filter
float4 delta2 = (c1+2.0*c4+c6-c3-2.0*c5-c8); //垂直sobel filter
float value = mul (delta1.xyz,delta1.xyz);
value += mul (delta2.xyz,delta2.xyz); //由于是rgb3个分量,所以求模长平方来确定绝对值大小,不做sqrt为了节省计算资源
float colorsat = saturate(1.3-3.0*value); //设定饱和曲线,可见,由sobel filter确定的边缘处(value较大)colorsat为0,而非边缘处(value接近0)则为1
return c0+float4(colorsat,colorsat,colorsat,0.0); //饱和原色,非边缘处,颜色将会饱和至白色,而边缘处,颜色不变。所以带有颜色的描边便显示出来。
}
其他的,比如sharpen filter,gaussian blur filter等等实现方法也是类似,只要知道滤波核,剩下的不过是:1:用纹理坐标偏移+tex2D得出滤波核对应的texel,2:乘上滤波核的权重因子并相加。即可
十:硬件,性能的考虑(这部分相对而言专业化一些)
由于MPC中的HLSL最终是由GPU硬件执行,所以硬件特性和执行效率就是必须考虑的问题。
首先我们需要考虑HLSL指令和最终生成的GPU指令的对应关系,从而对HLSL代码实际执行指令长度有一个大致估计。
就GPU而言,其pixel shader执行单元可以认为是一系列的矢量处理器配上标量处理器再加上纹理单元构成。所谓矢量处理器,所执行的GPU运算诸如(以下是GPU汇编指令,和HLSL指令有区别)
add——vec1+vec2——矢量对位相加
mul——vec1*vec2——矢量对位相乘
mad——vec1*vec2+vec3——矢量对位乘加
dp3——vec1.x*vec2.x+vec1.y*vec2.y+vec1.z*vec2.z——矢量点积
等运算,而标量单元负责的是诸如
pow——scar1^scar2——标量幂运算
rcp——1.0/scar1——标量倒数运算
rsq——1.0/sqrt(scar1)——标量方根倒数
log——log2(scar1)——2为底的对数
等等
而纹理单元,执行的自然是
texld——纹理采样函数
下面列举一些HLSL指令对应的GPU指令数量和性质
float4 v1 = v2 + v3;——一条GPU加法指令
而float4 v1 = v2 + v3 + v4;——两条GPU加法指令
float4 v1 = v2 * v3 + v4;——一条GPU乘加指令
float4 v1 = mul(float4(v2),float4x4(m1));——一条GPU乘法mul加上3条GPU乘加mad。
而
float s1 = s2/s3——一条GPU标量倒数rcp加上一条GPU乘法
float s1 = sqrt(s2)——一条GPU标量平方根倒数rsq加上一条GPU标量倒数rcp
float3 v1 = pow(float3(v2),float3(v3) )——三条GPU标量指数运算
float3 v1 = float3(v2)/float3(v3)——三条GPU标量倒数+一条GPU矢量乘法
比如
tex2D(s0,tex)——一条纹理取样函数,无dependent texture read
tex2D(s0,tex+float2(0.6,-0.6))——一条矢量加法加上一条纹理取样,一级dependent texture read
tex2D(s0,tex+tex2D(s0,tex+float2(0.6,0.6)).xy)——两条矢量加法加上两条纹理取样指令,两级dependent texture read
tex2D(s0,tex+tex2D(s0,tex).xy)+v1——两条矢量加法加上两条纹理取样,一级dependent texture read
等等……
在MPC的HLSL编译目标(compile target)选项中,有意义的包括ps_1_1,ps_1_3,ps_1_4,ps_2_0,ps_3_0。HLSL code的结构复杂度、指令的复杂性、指令数多寡决定了它最低需要的编译目标。
ps_1_1和ps_1_3在实际应用中差别甚微。都属于限制非常大的编译目标,主要限制是:
1:最大指令数目限制严重,不能超过8条算术指令(尽管其实可以不超过3维的矢量运算与标量运算并发(co-issue)所以最多是16条算术指令,但是不用指望HLSL编译器能够强大到如此程度)和4条纹理指令(ps1.1-1.3的纹理指令其实比较复杂,属于组合功能方式,但是在MPC中基本用不上)
2:无复杂运算指令,诸如rcp,rsq,log,pow等全部没有
3:寄存器数值范围很窄,比如float s1 = 1.5 * s2;就会自动变成float s1 = 1.0 * s2;(也就是1.5超出了范围),只能写成float s1 = s2+0.5*s2;才能正确编译
4:无dependent texture read。而tex基本可以认为无法操作
5:分支什么的就基本不用指望了。除了像if(s1>0.0){s2 = 1.0;}else{s2 = 0.0;}这种极其简单的。
ps_1_1级别的硬件,比较流行的是Nvidia Geforce 3
ps_1_3级别的硬件,比较流行的是Nvidia Geforce 4Ti
ps_1_4比ps_1_3适应性广一些包括
1:最大指令数限制有所松动,算术指令翻倍,纹理指令翻2倍。
2:支持一定限度的dependent texture read(1级),tex可以进行一定程度的操作
ps_1_4级别的硬件,比较流行的是ATI Radeon8500,9000-9200
事实上,由于ps1.x属于定点数结构,所以有一些移位指令可以使用,比如mul_x2,add_x2代表将结果相加后左移一位,相当于乘二。这也是为何第六节的第四个程序有ps1.x版本的原因。不过说到底,ps1.x不是为HLSL准备的。
ps_2_0是HLSL诞生时的默认编译对象
1:支持绝大多数的HLSL函数。
2:64条算术指令,32条纹理指令,最多4级的dependent texture read
3:全部浮点流水线,数据范围精度增强。
4:尽管ps_2_0没有硬件支持的动态分支,不过可以实现一定程度的分支,只不过每个分支都要跑一遍。也就是效率不会很高
ps_2_0级别的硬件包括Nvidia GeforceFx系列(ps_2_a)ATI Radeon 9500及以上X700以下(ps_2_0)X700,X800,X850系列(ps_2_b)
ps_3_0是当前PC上的最高pixel shader版本
1:比ps_2_0增加了一些指令
2:硬件支持分支,循环
3:最大指令数大大增加,不再有纹理算术指令数量分配的限制
4:dependent texture read级数没有限制
ps_3_0级别硬件包括Nvidia Geforce 6系列,7系列,ATI Radeon X1xxx系列
所以,编写HLSL请考虑自身硬件的功能等级。
以下是一些简单的提升性能的考虑
1:如果可以,使用ps1.x编译对象能获得最佳性能,如果该HLSL code不能使用ps1.x编译对象,那么请使用可用的最高ps版本的编译对象,如Geforce6系列就请使用ps_3_0编译对象。
2:在许可的情况下尽量减少使用复杂运算指令,诸如pow,sin,cos,asin,acos,sqrt等。
3:对于Nvidia Geforce Fx和6系列,推荐将float(FP32)替换为half(FP16)以提高性能。
4:对于向量来说,选择需要的最小维数,比如能用float3(half3)就不要用float4(half4),能用标量就不要用矢量
5:动态分支不要太多,除非你用的是X1800XT……
附:一些相关资料
HLSL参考:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/directx9_c/dx9_graphics_reference_hlsl.asp
DirectShow相关
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/directshow/htm/directshow.asp
一篇不错的介绍数字图像处理的文章
http://www.gamedev.net/reference/articles/article2007.asp